4. Open Datasets
Welcome to Day 04 of Developer Tools Week as we continue our learning journey into Data Science! Today, let’s talk about finding inspiration from the open source community by exploring open datasets and learning resources.
What We’ll Learn
- What is Exploratory Data Analysis (EDA?
- Explore Datasets on Kaggle.
- Explore Datasets on Hugging Face.
- Explore Datasets on Microsoft Azure
- Assignment: Enrich data with Azure Open Datasets
- Resources: Explore the 2024: Data Science Day Collection

In previous posts, we walked through tools to set up a consistent pre-built development environment, and establish a Data Science profile for productive coding. Now that we have our developer tools in place, let’s talk about what explorataory data analysis involves and how we can practice this approach with open datasets.
1. What is Exploratory Data Analysis (EDA)?
Once you have a dataset, the first step is to analyze it in a way that helps you understand its main characteristics. This is where Exploratory Data Analysis (EDA) comes in. It’s an approach that uses visualization tools and techniques to help us understand the data, identify patterns, and relationships between variables, and detect outliers or missing values. This process can then guide us in making necessary decisions to build a predictive model with that data.
A typical EDA workflow involves:
- Loading data into a data frame
- Cleaning data by handling missing values and outliers
- Visualizing data using plots and charts
- Analyzing data to identify patterns and relationships
- Summarizing data to draw insights
To understand how this works, it helps to have a real data set to work with - and then create a Jupyter notebook to walk through these steps interactively. But finding good datasets for data science work can be challenging. This is where open datasets come in handy.
2. Open Datasets & Communities
Open datasets are publicly available datasets that are curated by community or organizations, and shared for use in research and learning projects. They typically cover a wide range of real-world application domains from finance and healthcare, to environment and sports - giving learners like us a rich source of data and inspiration to practice our data science skills.
One of the side-benefits of open datasets is the community that forms around them, that you can learn from. Want to get a sense for what an exploratory data analysis is? Find a community-authored notebook for an open dataset, and study it to get familiar with the libraries used, the visualizations created, and the insights drawn from the data. Then, pick a new dataset and work through the steps on your own.
Let’s look at three of my favorite sources for open datasets and community-driven learning.
2. Datasets on Kaggle
Kaggle is one of the most popular platforms and communities for machine learning and data science learners, developers and researchers. According to the site, it currently has 18M+ users, 309K datasets, 1M+ notebooks and 2.5K+ trained models - all shared by the community. As a learner, there are some features that are particularly helpful:
- Community Notebooks: Members share their work in public notebooks, which you can then study, run on their platform, and discuss with others - to build your own intuition.
- Co-hosted Competitions: Kaggle is known for data science compeititions that can challenge you to build your skillset by applying what you learn to real-world problems.
- Certification Courses: Structured courses that guide you through various skills needed for data science projects, with an option to get certifications for your professional profile.
Learn data analysis by doing exercises with real datasets. For instance, I am a huge fan of cricket (sport). So here are three steps I can take to get started on a data analysis journey for cricket data:
- Find a dataset - This IPL 2022-Dataset looked interesting.
- Explore notebooks - This Community EDA Tutorial inspired me.
- Explore models - This Score Prediction Model gave me ideas.
Now, I can build my intuition by running and remixing these notebooks - or apply my learnings to new datasets, transferring that knowledge.
3. Datasets on Hugging Face
While Kaggle focuses on the broader data science community, Hugging Face targets more advanced learners and researchers with a community that is focused on natural language processing (NLP), deep learning and generative AI. The platform provides a hub for finding models, datasets, and Spaces (hosted demos) created by the community.
Here are three resources to explore first on Hugging Face:
-
Datasets: Find datasets shared by the community for use in machine learning tasks like text classification, image classification, object detection, text retrieval, question answering and more.
-
Datasets Library: A Python library for streamlining data processing tasks for training machine learning models.
-
Quickstart Tutorial to guide you through the steps of using the library with a published dataset. And extensive how-to guides to handle more complex tasks building on those fundamentals.
4. Datasets on Microsoft Azure
As you progress in your data science journey, you will also need to understand how to operationalize your data science workflows - from enriching your machine learning models with richer datasets, to deploying them to production environments.
The Azure Open Datasets platform supports this journey with a collection of curated and cleansed datasets that are ready for use (with minimal preparation) in your data science and machine learning projects.
The Azure Open Datasets Catalog shows available datasets with public-domain data for weather, census, holidays, public safety, and location - grouped by application domains like Transportation, Health, Labor, Population and more. You can access datasets through APIs, and also contribute your own datasets back to the platform.
5. Try It: Azure Open Datasets
The figure shows the components of the Open Datasets service that help streamline the use of these datasets in your production workflows on Azure, using the Python SDK.
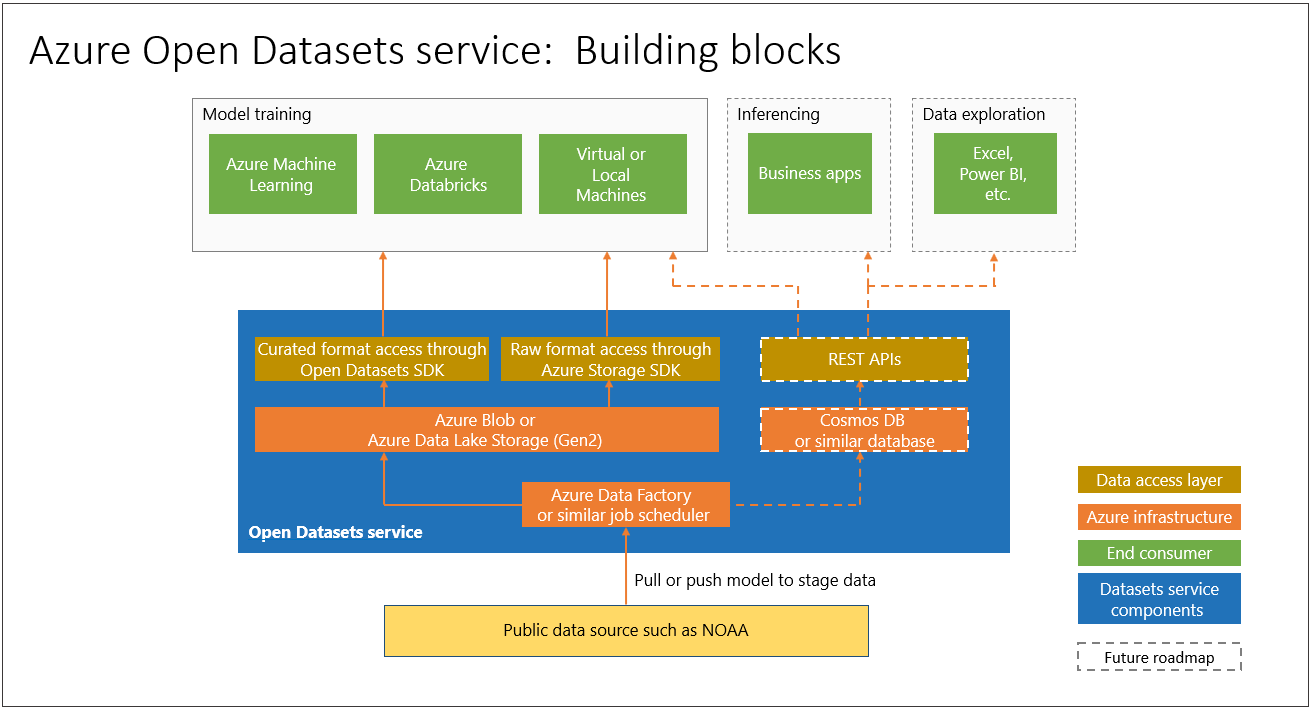
Try exploring these yourself to gain more intuition into operationalizing data science workflows with cloud services. You will need an Azure subscription - set up a free account if you need one.
- Use this tutorial to learn how to train a regression model with AutoML and the Python SDK.
- Use these sample notebooks to learn how to enrich data for your machine learning models.