2. Visual Studio Code
Welcome to the second post of Developer Tools Week as we continue our learning journey into Data Science! Today, let’s talk about how we can get more productive by using Visual Studio Code as our editor, and creating a Data Science Profile for consistency and collaboration across projects and users.
What We’ll Learn
- Why use Visual Studio Code?
- What is a VS Code Profile?
- How do I create a Data Science Profile?
- What is Data Wrangler?
- How can I use Data Wrangler for Data Analysis?
- Assignment: Complete the Data Science in VS Code Tutorial
- Resources: Explore the 2024: Data Science Day Collection

In the last post we talked about GitHub Codespaces and how it helps create a reproducible development environment with minimal setup effort on your part. Today, we’ll look at why [Visual Studio Code] (https://code.visualstudio.com/docs) is the perfect IDE (editor) for your data science projects in this environment.
1. Why Visual Studio Code?
We already saw how the dev container approach involved a Visual Studio Code client (in browser or on local device) connecting to a pre-built Docker container (hosted in GitHub Codespaces or Docker Desktop) to give us a familiar and seamless developer experience. But there are three more reasons why it’s ideal for Data Science projects:
- Jupyter Notebooks are supported natively in VS Code, making it easy to run and debug code in notebooks in a familiar environment.
- VS Code Profiles let you create a reusable profile (defining settings, extensions and customizations) that can be shared across projects and users.
- Data Wrangler is a code-centric data viewing and cleaning tool with a rich UI to view, clean & analyze data, and automatically generate Pandas code to perform the same operations.
Let’s explore these capabilities briefly in the next couple of sections, then revisit the Visual Studio Code tutorial for data science using the Jupyter-Codespaces environment we set up in our workshop repository in the previous post.
2. Data Science Profile
If you are a frequent user of Visual Studio Code (e.g., content creation, programming in other languages, working with GitHub Codespaces) then you likely have Profiles setup for distinct contexts, to make you productive. By default, a profile lets you specify the settings, extensions and other customizations you want to use for a given context in a manner that is reusable and shareable across users and projects.
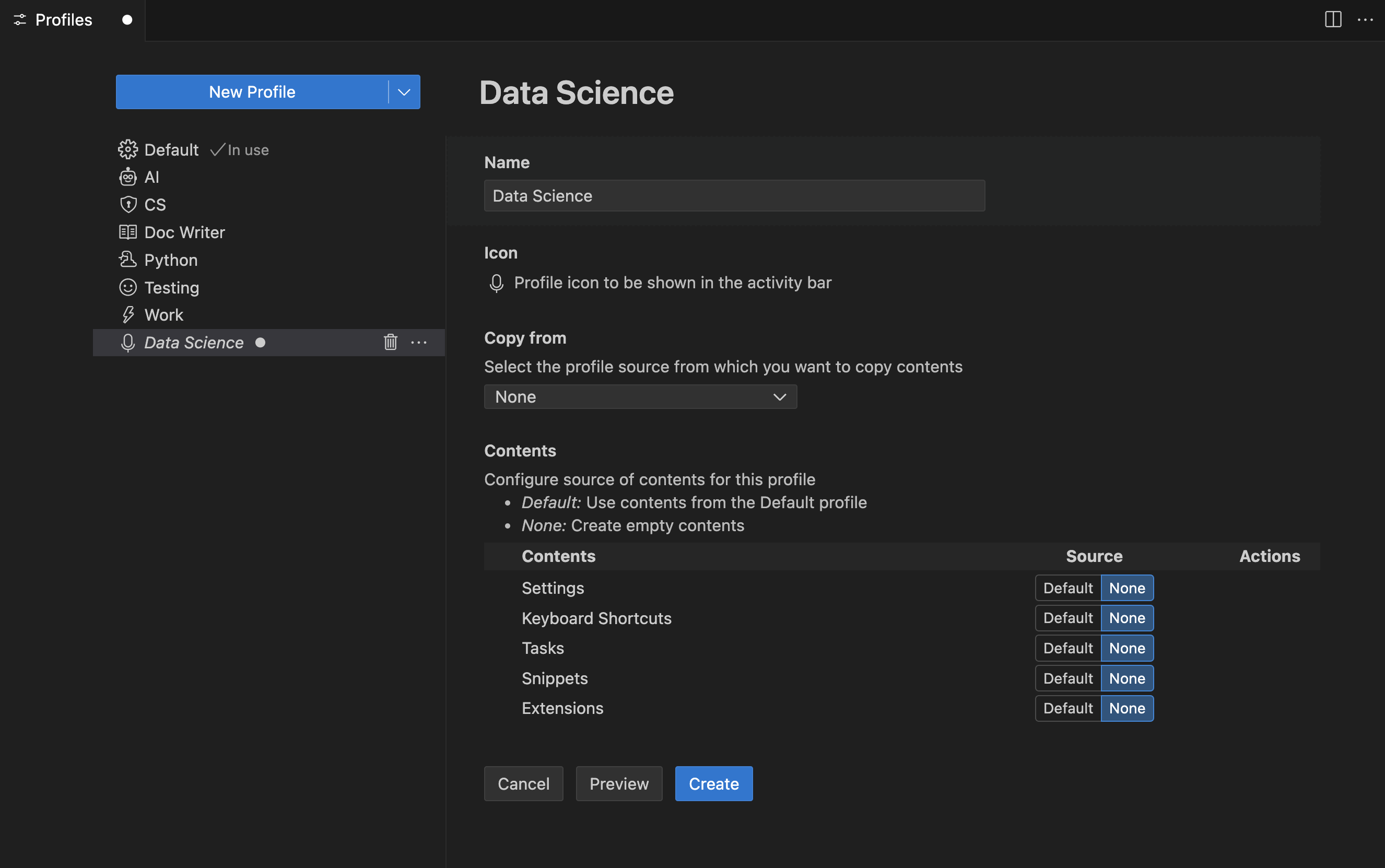
You can create a profile from the Command Palette (as shown above) or by clicking the gear icon in your sidebar and selecting the Profiles (Default) menu option. Once created, you can easily switch between profiles with a single click, making it easier to keep distinct yet customized editing preferences and dependencies for each project or domain you work in. You can also export profiles to either a Gist (online) or a file (local device) that others can then import to replicate your settings.
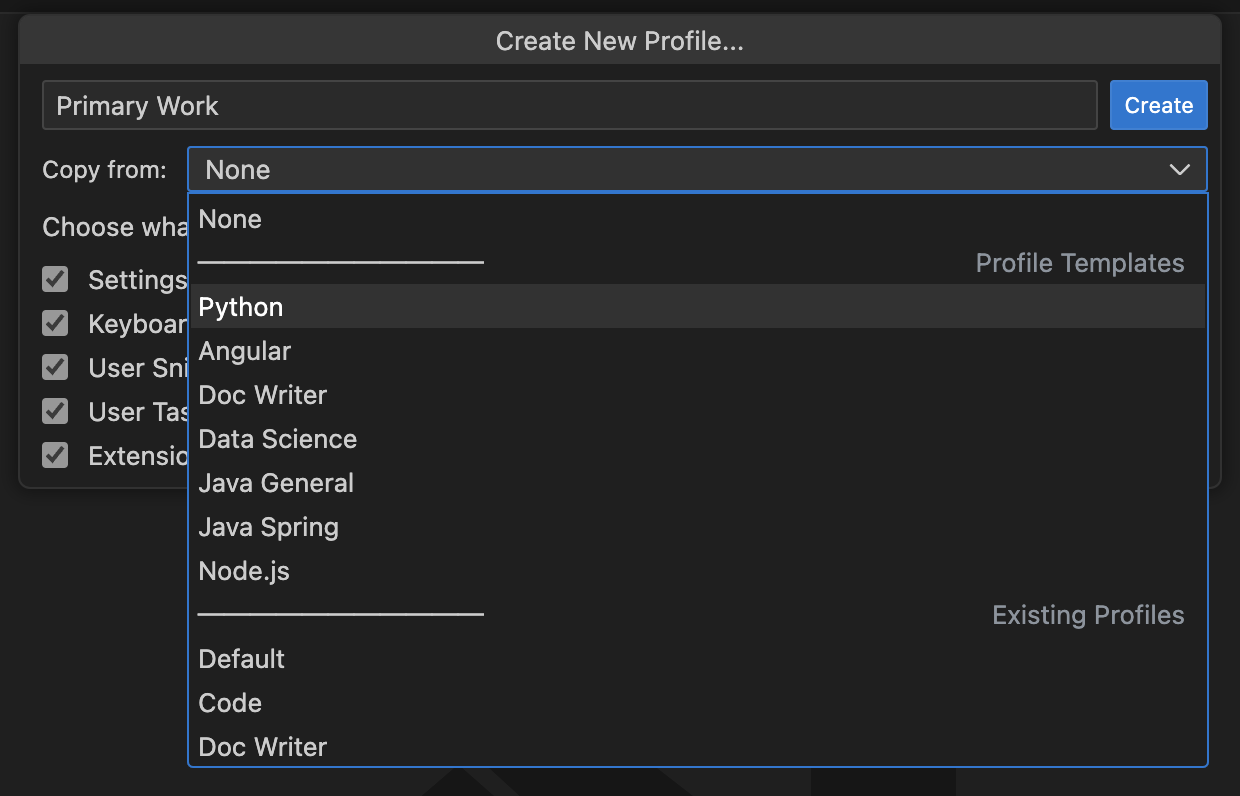
Visual Studio Code comes with curated profile templates that are pre-configured for popular extensions and capabilities, that you can use as the basis for creating your own. For example, the Data Science profile template has built-in support for Dev Containers, Jupyter, Python, GitHub Copilot, Data Wrangler etc, - giving us the solid foundation required for use in our Jupyter-Codespaces environment.
3. Data Wrangler Extension
You may have observed that the Data Science Profile has a Data Wrangler Extension included by default. What is it and why should we care? Data Wrangler is a code-centric tool for data viewing, cleaning and analyzing - that works seamlessly with data files you open in Visual Studio Code.
More importantly, it can automatically generate Pandas code to perform the same operations you perform in the UI, with easy ways to copy the code into a Jupyter Notebook or clipboard, to simplify your data analysis workflow even further. As a bonus, the extension automatically creates action buttons within your Jupyter Notebooks in contexts where a Pandas DataFrame is returned.
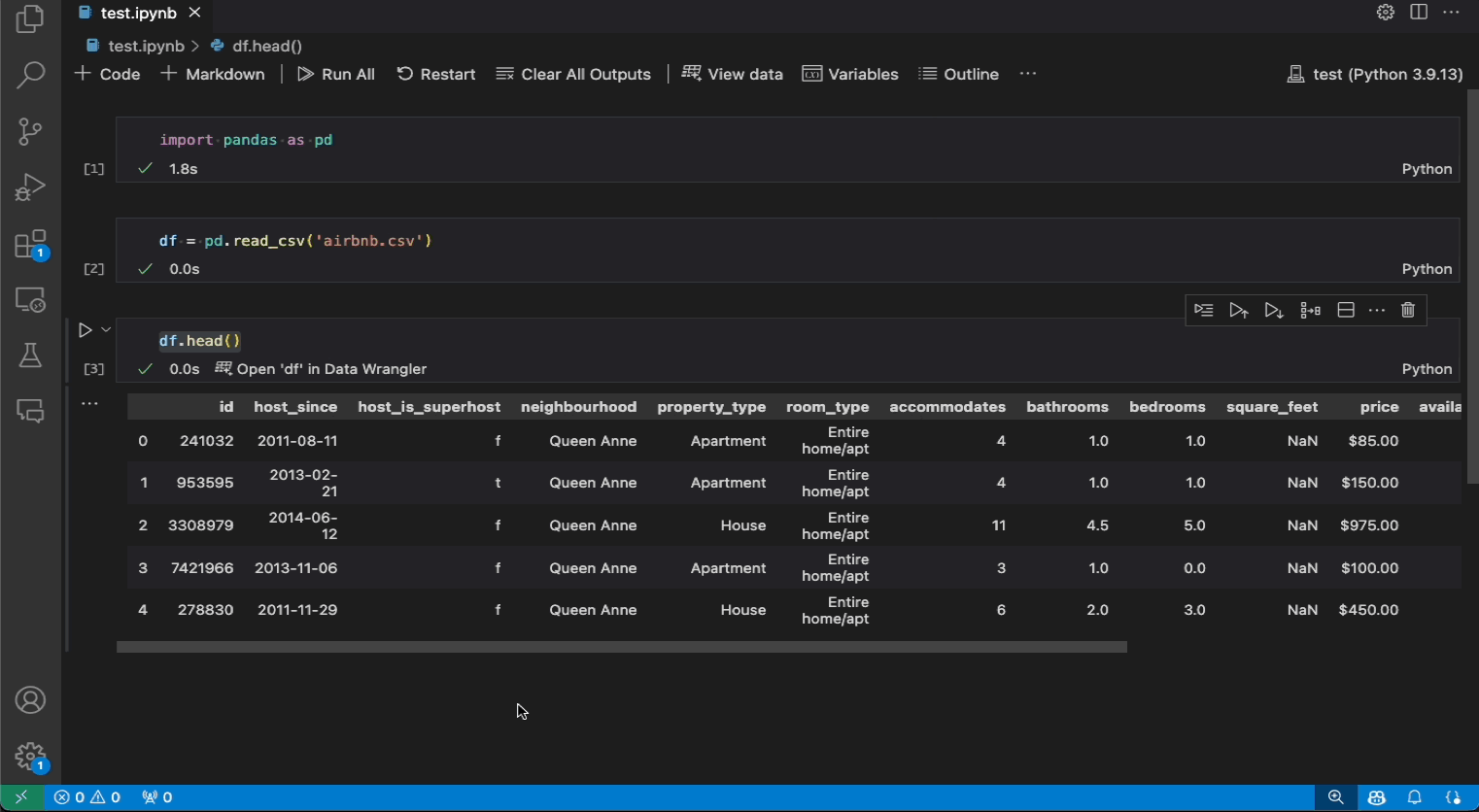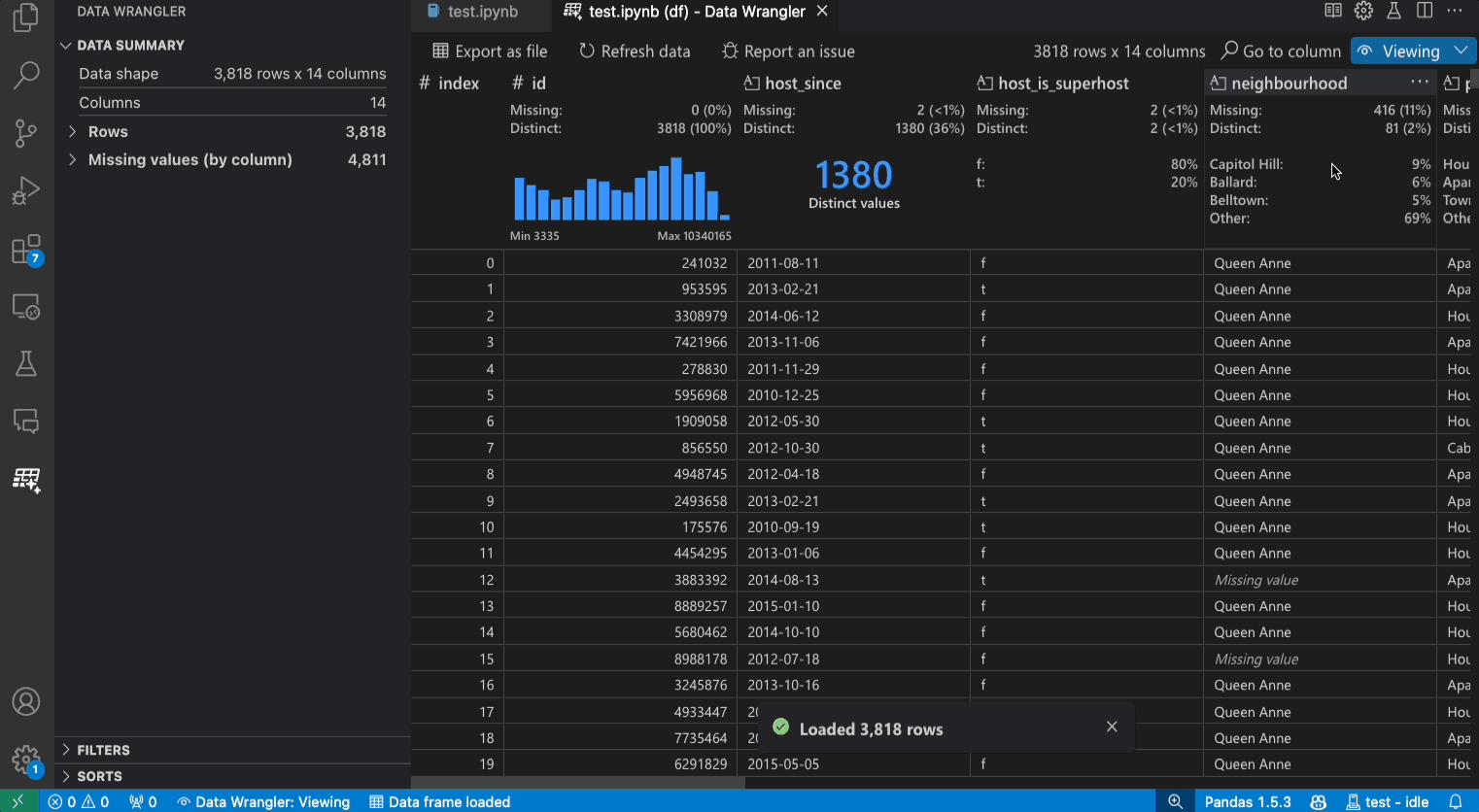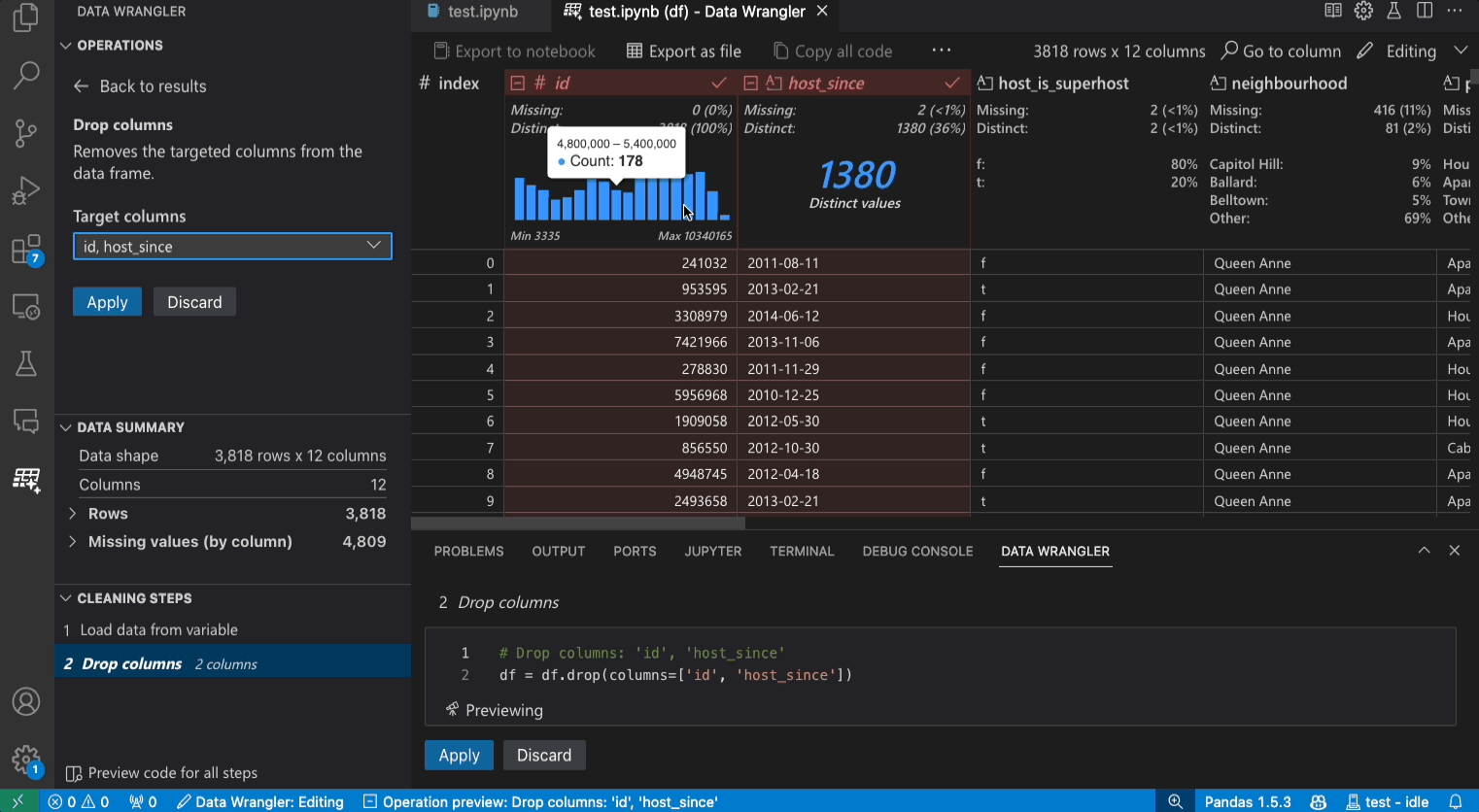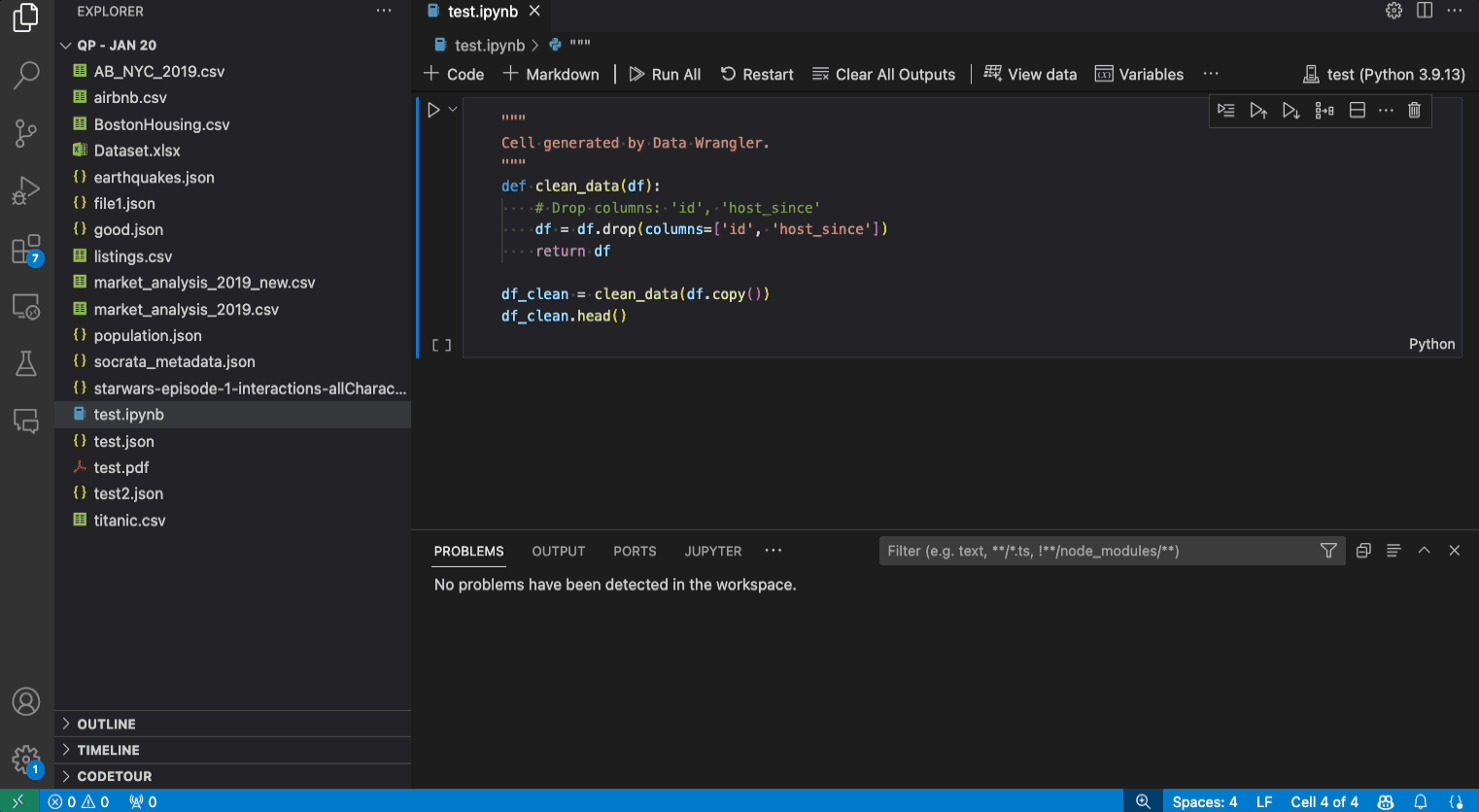
Clicking this opens a new Data Wrangler view as shown, allowing you to visually and interactively run operations to clean, filter, sort and analyze your data - before exporting generated code back to the Jupyter notebook into a Python cell exactly where you need it. This is a great way to learn core Pandas operations for data cleaning, and build intuition around the right operations to use for your data. And, it allows you to document and share these steps with others in a reproducible manner.
4. Data Science Tutorial
Let’s bring all these elements together and see how Visual Studio Code works in practice for enhanching our Data Science journey. First, take a minute to review the Data Science section of the Visual Studio Code documentation.
Then, review the Data Science in VS Code Tutorial to get a sense of what you will learn by completing these steps using the Jupyter-Codespaces environment we set up earlier. The tutorial covers four stages of a data science workflow that we can adapt to our needs:
- Setup your environment - we’ll use our Jupyter-Codespaces template
- Prepare the data - we’ll launch Data Wrangler from the notebook
- Train & evaluate - using scikit-learn (we’ll revisit later)
- Use a neural network - using Keras and TensorFlow (we’ll revisit later)
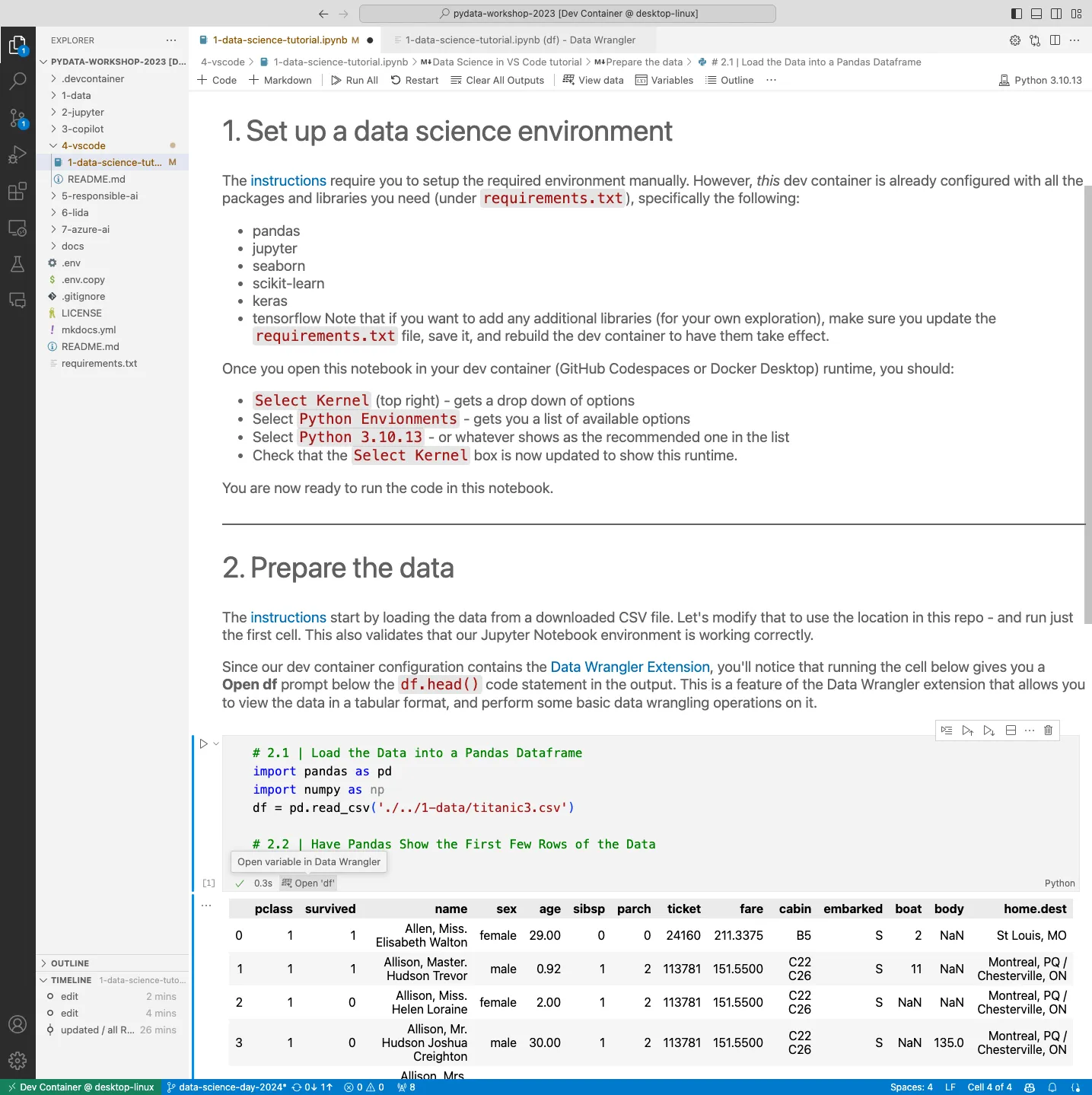
To make this easier, I’ve created a data-science-tutorial notebook under the 4-vscode/ folder in the workshop repository with the first two stages of the tutorial completed as shown. Observe how the df.head() output now shows a Data Wrangler button below that launches the Data Wrangler view when clicked.
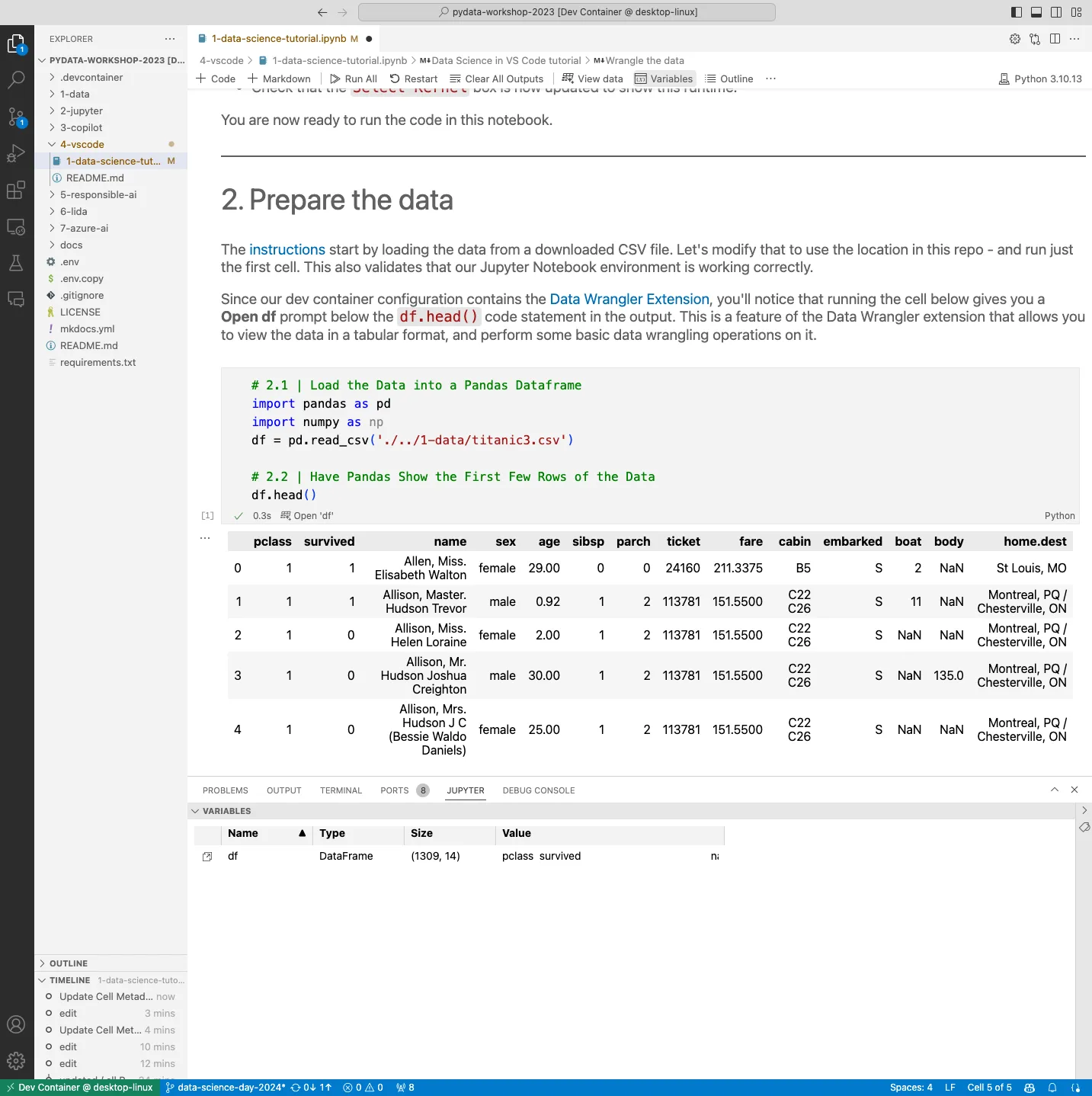
Here is a screesnhot showing how we can switch the Data Wrangler into Editing view, to perform operations on the data (e.g., sort, filter, group). These operations are recorded as Cleaning Steps (see sidebar lower left), with the code for each step auto-generated in the Data Wrangler pane (bottom, right). and then Export the generated code back to the notebook. When the steps are complete, then Export to notebook (see menu option, top) to get the code automatically inserted into a Python code cell in the notebook.
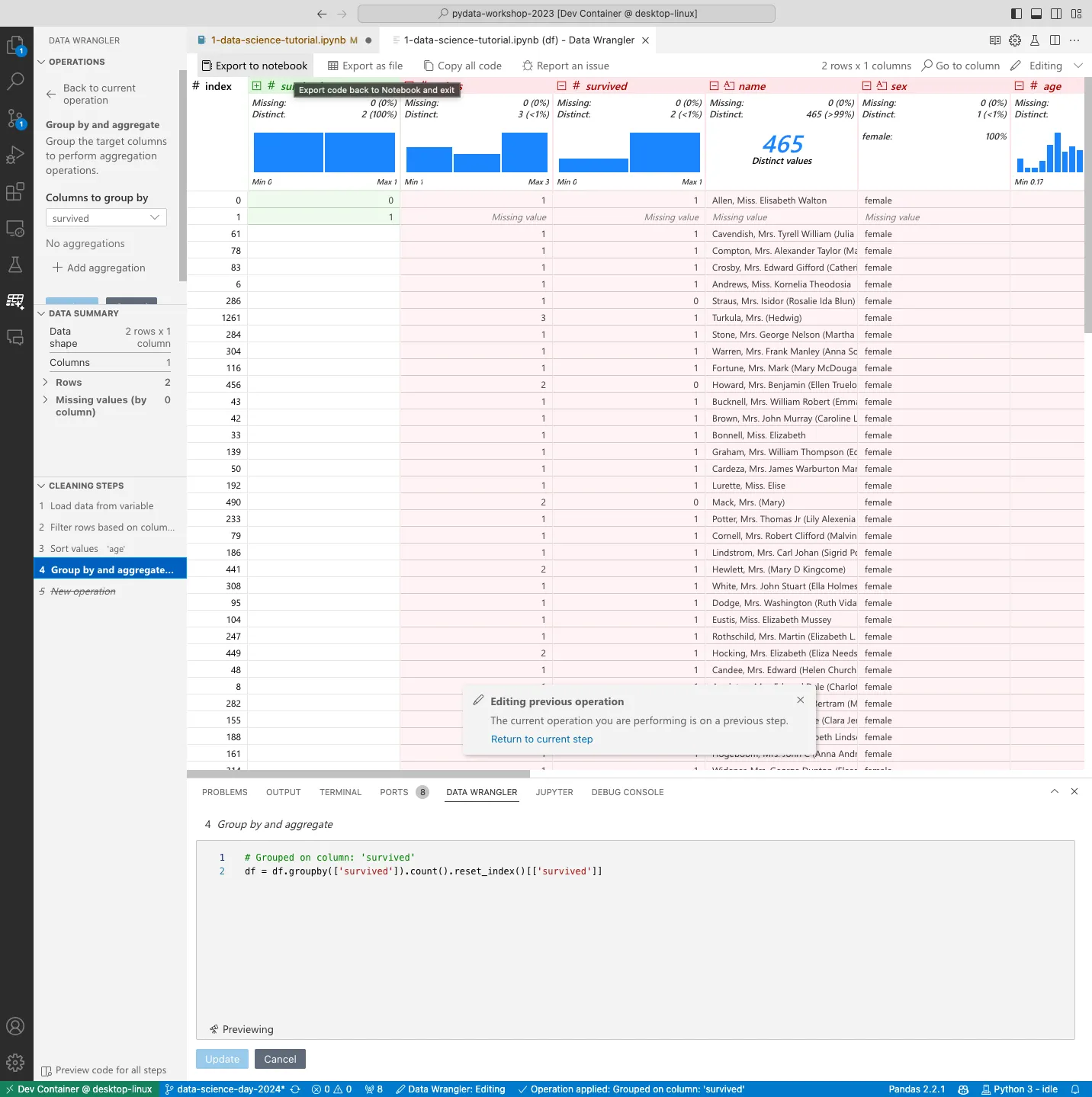
Use the notebook as a sandbox to explore various operations interactively on the data file - and observe how the Pandas code generated matches the requirement.
5. Assignment: Try it out!
It’s your turn. Fork the repo, launch it in GitHub Codespaces, then open the 4-vscode /1-data-science-tutorial.ipynb notebook. You should see something like this - but with Select Kernel at the top right.
- First, “Clear all outputs” to start fresh
- Then, “Select Kernel” and chose the default Python environment
- Then “Run All” to view the outputs from each cell.
By completing the tutorial, you will not only get a good understanding of the steps involved in each stage, but you will end up with a notebook template you can reuse with other datasets, to experiment further and build your intuition.
In our next post, we’ll explore the use of GitHub Copilot to automate the generation of notebooks, get explanations for code - and suggestions to build our intuition organicially - using this tutorial as a basis.